dataviz avec R et shiny
Dans les sujets autour de la gestion de la donnée on trouve bien entendu tous ceux en rapport avec le traitement, le stockage des données dans des entrepôts mais ce qui m’intéresse ici c’est la présentation ou la dataviz.

Introduction
On peut faire des choses compliquées avec des outils spécialisés, des solutions du marché, tenter de rapprocher traitement et présentation ou séparer le premier du second. On peut faire également des choses assez simples en matière de présentation, sur le web, des résultats de ses travaux de traitement. Ce qui est plus sympa encore c’est de donner un peu la main à l’utilisateur en lui permettant d’explorer les données présentées, via des filtres, des facettes et des représentations adaptées à l’exploration.
Parmi les solutions s’offrant à nous, je vous présente ici la solution adossée au langage R et qui permet de monter des petits sites web simples : R shiny. Vous trouverez plein de documentation à ce sujet et notamment sur le site de l’éditeur des jolies représentations. Je vous propose en quelques articles de vous présenter comment cela fonctionne, ce que l’on peut faire simplement avec cette solution et comment l’intégrer dans un écosystème un peu plus vaste, notamment dans des conteneurs pour l’hébergement et avec des libraires graphiques plus évoluées pour disposer de présentations plus agréables.
On démarre dans ce billet par les principes de base, l’outillage pour travailler, construire et tester ses premières dataviz.
- article suivant : analyse de données avec R shiny
Exemple présenté
Plutôt que de partir sur une réalisation déjà existante, je vous propose une approche pas à pas à partir de R, de données déjà présentes en standard dans la solution et d’outils disponibles sans investissement.
Si vous souhaitez voir directement le résultat final, je vous invite à consulter la première dataviz directement sur un site web monté à cet effet et dédié à la qualité de l’air : airqual 1. Vous trouverez également les sources sur mon git.
Outillage
Pour réaliser cette première dataviz, il n’est nécessaire que de disposer sur son poste de travail d’une installation de R et de Rstudio, à adapter en fonction de votre plate-forme. RStudio dispose d’un mode de construction d’une dataviz directement lors de la création d’un nouveau projet : Shiny web application.
Pour démarrer, je vous conseille de n’utiliser qu’un seul fichier (nommé app.R), c’est plus simple à gérer, même si moins lisible.
Si vous avez cloné les fichiers depuis le repo git, vous pouvez directement ouvrir le répertoire 01-airqual dans RStudio, le fichier app.R est autoporteur.
A partir du fichier app.R dans l’éditeur, vous pouvez directement lancer l’application avec le bouton Run App en haut de la fenêtre, ce sera plus simple pour suivre.
Principe de fonctionnement
La construction
Une application shiny est découpée en deux modules principaux : l’interface utilisateur et le serveur de calcul. La partie UI permet de décrire l’interface web qui sera présentée à l’utilisateur, d’y positionner les objets (input et output) au sein de composants d’interface (layout).
Le langage est du R tout simplement, si vous ne connaissez pas déjà, c’est l’occasion d’apprendre à faire quelques manipulations de données simplement, vous pouvez à partir de maintenant oublier les opérations manuelles avec votre tableur préféré. Ce n’est pas la seule solution simple pour manipuler de la donnée via un langage de programmation assez simple, on trouve également beaucoup de choses disponibles dans la galaxie python.
Ce que va présenter notre dataviz est très simpliste :
- une zone de filtrage sur la base du mois de mesure
- un affichage des paires de valeurs sur l’ensemble des données à l’exception du jour de mesure
- un tableau avec les premières valeurs
Le but étant de montrer les 2 modules (input et output), leur interaction et la simplicité de présentation sur des objets simples.
Le traitement
Pour cet exemple trivial j’utilise les données dans le data set airquality qui représentent des mesures effectuées à New York en 1973 de quelques valeurs comme l’ozone, la vitesse du vent, la température et l’ensoleillement. Cet échantillon est composé de 153 lignes de 6 données. Ce n’est pas là que R est le plus évident, mais qui peut le plus…
Si vous ne connaissez pas déjà R, voici les quelques outils nécessaires à la compréhension de la partie serveur du code.
Les données
Dans l’interpréteur R du RStudio :
1> d <- airquality
2> head(d)
3 Ozone Solar.R Wind Temp Month Day
41 41 190 7.4 67 5 1
52 36 118 8.0 72 5 2
63 12 149 12.6 74 5 3
74 18 313 11.5 62 5 4
85 NA NA 14.3 56 5 5
96 28 NA 14.9 66 5 6
- ligne 1 : chargement des données du data set airquality dans la variable
d, on pourrait directement utiliser airquality, mais c’est bien plus long à manipuler - ligne 2 : on affiche les premières lignes du data set
Les données seront affichées sur la base du filtrage sur les mois proposé dans la partie input de notre outil de dataviz. Le filtrage s’effectue sur la colonne proposant le mois et sur la base des 2 bornes du filtre (a et b ici) :
d <- d[d$Month >= a & d$Month <= b, ]
Le data set est à 2 dimensions, ici on filtre sur le contenu de la colonne Month pour l’ensemble des lignes en appliquant le filtre.
Le tableau
Le tableau des données sera affiché en l’état, on ne prendra en revanche que les premières données (avec head).
Le graphique
Pour le graphique, on filtre les données pour supprimer les jours puis on affiche. Les jours de mesure étant positionnés dans la dernière colonne, on la supprime simplement.
d <- airquality[,1:5]
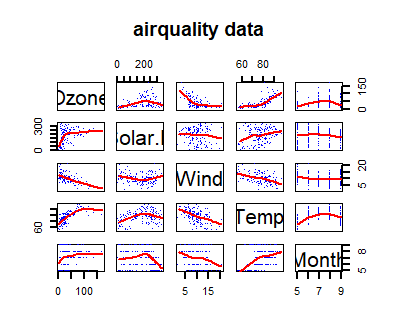
L’affichage du comparateur des paires de données est basé sur l’outil pairs qui construit automatiquement une matrice de graphes de dispersion, ceci permet rapidement de constater (ou pas) des corrélations entre des variables de notre ensemble de données.
> pairs(d,
panel = panel.smooth,
pch=".", lwd = 2,
col = "blue",
main = "airquality data")
Le code
L’interface utilisateur
Puisque l’on souhaite une interface proposant une zone de manipulation des données et une zone d’affichage, le modèle simple est celui proposé par sidebarLayout avec une panneau pour les inputs et un autre pour la partie principale. Le nom des objets input et output est important car il servira de clé à la partie serveur.
1sidebarLayout(
2 sidebarPanel(
3 sliderInput("month",
4 "Month:",
5 min = 5,
6 max = 9,
7 value = c(5,9))
8 ),
9
10 # Show a plot of the generated distribution
11 mainPanel(
12 plotOutput("pairs"),
13 tableOutput("values")
14 )
15 )
- ligne 3 : mise en place du sélectionneur de mois, ici, on connait les données on peut donc positionner les bornes et les valeurs par défaut : 5 et 9. Le slider est nommé
month - ligne 11 : le panneau principal propose les 2 représentations : le graphique nommé
pairset la zone de tableau nomméevalues.
Les deux zones de représentation utilisent des objets output dédiés à l’usage souhaité, on trouvera en complément de quoi afficher du html, du texte brut, un bouton pour télécharger des données.
Le serveur
La partie serveur sera utilisée lorsque des données sont chargées ou modifiées par le biais d’une zone input. Seul le code utilisant la partie input modifiée sera exécuté, c’est donc plutôt frugal et bien pensé.
Dans la partie serveur on trouve de quoi peupler les 2 zones output décrites dans l’UI, chacune des fonctions retournant le contenu à afficher, dans notre cas une image et des données pour un tableau.
Affichage de la partie graphique dans la zone pairs de l’output, le filtrage s’effectue en récupérant les valeurs min et max du slider (dans input) :
output$pairs <- renderPlot({
d <- airquality[,1:5]
d <- d[d$Month >= input$month[1] & d$Month <= input$month[2], ]
pairs(d, panel = panel.smooth,
pch=".", lwd = 2, col = "blue",
main = "airquality data")
})
Affichage de la partie tableau (values) avec les 10 premières lignes de notre data set :
output$values <- renderTable({
d <- airquality
d <- d[d$Month >= input$month[1] & d$Month <= input$month[2], ]
head(d[order(d$Month, d$Day),], n=10)
})
Conclusion
Voilà en quelques lignes de code R de quoi faire une petite interface graphique simple, disponible sur votre intranet par exemple et permettant de présenter et de manipuler les données. Ce qu’il faut garder à l’esprit est que l’on peut donc simplement combiner la puissance du langage R dans le domaine de la manipulation des données et un procédé très simple de représentation. Nous verrons dans un prochain billet comment héberger ceci pour son intranet ou le rendre disponible au plus grand nombre.
Photo from rawpixel
l’hébergement sur shinyapps dépend de l’usage et des crédits sur le compte, j’utilise la version free et ais positionné les paramètres au plus bas (temps de mise en veille et dimensionnement) ↩︎