analyse de données avec R shiny
Après une courte introduction à l’outil shiny de présentation des données travaillées avec le langage R, voici une version plus aboutie complétant quelques concepts de cette solution de dataviz.
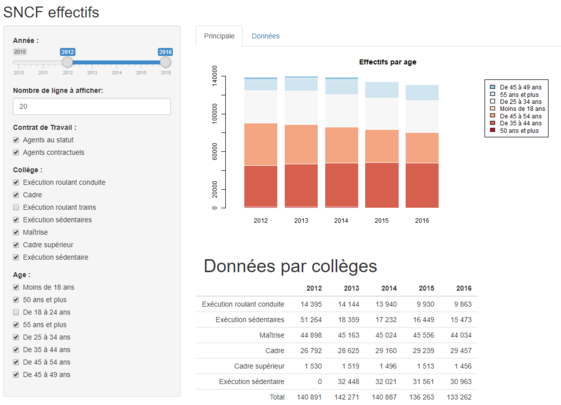
Pour cet exemple je vous propose d’utiliser des données misent en open data par la SNCF sur ses effectifs. Les données proposées représentent 444 lignes de 5 variables, couvrent une période de 2010 à 2016 sur le nombre d’effectifs du personnel de la SNCF avec un détail sur les contrats de travail, les collèges et les tranches d’age. Pas encore de quoi perturber le langage R dans la manipulation des données, mais cela va nous permettre de jouer avec de vraies données et d’apporter quelques améliorations à notre dataviz précédente. Dans le meilleur des cas vous apprendrez peut-être des choses sur la SNCF et la composition de ses effectifs ;)
Le code de l’application est disponible sur mon git dans le répertoire 02-sncf si vous souhaitez suivre en ligne ou partir de cet exemple pour vos propres dataviz.
Composition de l’application
Contrairement à notre premier exemple, j’ai découpé le code de cette application un peu plus grosse en plusieurs fichiers. Le fichier app.R utilisé précédemment est cette fois-ci réparti sur les fichiers ui.R et server.R, le premier contenant donc les éléments de l’interface utilisateur et le second la partie relative à la manipulation des données. En complément, j’utilise un fichier global.R afin de charger les données initiales, puisque proposées en open data, il faut les télécharger.
Dans ce dernier code, le fichier contenant les données est téléchargé et stocké en local afin que l’application puisse les réutiliser au prochain démarrage. Les données sont stockées dans un data set (dAge) dont les colonnes sont renommées afin de simplifier la manipulation (accents notamment).
Interface
La partie UI présente des filtres afin de raffiner les données présentées sur la partie droite de l’application. Chaque widget est paramétré directement à partir des données dans le data set, ce qui rend le code générique et autoriseraient les données à être mise à jour et l’interface s’adapter automatiquement. C’est bien l’objet principal de cet outil lorsque l’on expose une application que d’avoir la possibilité simplement de se rafraîchir avec des nouvelles données sans pour autant reprendre le code ou effectuer une manipulation manuelle.
Les éléments utilisés sont :
- un slider pour sélectionner la tranche de date de l’analyse (entre
min(dAge[1])etmax(dAge[1])) - une zone de saisie numérique avec des boutons d’incrément et de décrément permettant de limiter le nombre de lignes affichées sur le second onglet de la zone d’affichage
- 3 listes à cocher sur la base des valeurs présentes dans les 3 colonnes : contrat de travail, collège et tranche d’age
A chaque modification d’un filtre, les données sont retravaillées par le serveur et les affichages sur la partie droite de la fenêtre remis à jour sur la base des données ainsi remises à jour.
La zone de données est découpée en 2 onglets (principale et données) et proposant un graphique et un tableau sur le premier onglet, les données brutes (premières lignes uniquement) sur le second onglet.
Serveur et traitement des données
Variables réactives
En complément de l’utilisation des fonctions de type render* appliquées sur les objets d’interface définis dans la partie ui, j’utilise sur ce serveur des variables de type reactive qui ont la propriété de se mettre à jour lorsque nécessaire, notamment sur une sollicitation lors de la modification des paramètres de l’interface graphique.
Par exemple la section :
{% codeblock lang:R %}
dValues <- reactive({
d <- dAge[dAge$date >= input$year[1] & dAge$date <= input$year[2],]
d <- d[d$contrat %in% input$contrat,]
d <- d[d$age %in% input$age,]
d[d$college %in% input$college,]
})
{% endcodeblock %}
sera évaluée à chaque modification de valeur d’un composant de filtrage. La table retournée sera ainsi mise à jour et disponibles pour tous les objets suivants dans la variable dValues. Ici je filtre l’ensemble des données par rapport aux sélections afin de limiter l’espace de travail pour les représentations.
Fonctions
J’utilise également une fonction (f) qui pourra être réutilisée dans les deux variables également notée réactive que sont dGraph (pour le graphique avec des données axées sur la date) et dDataCollege avec des données à mettre dans le tableau et axées sur le collège. L’artifice de cette fonction permet de factoriser les traitements similaires à effectuer lorsque des données sont modifiées. Sinon, le code doit être dupliqué dans les objets render directement ce qui n’est pas optimal. A noter que nous avions dupliqué le code dans notre précédent exemple pour ne pas complexifier la compréhension.
f <- function(axe) {
d = dValues()
ta = unique(unlist(d[[axe]]))
[...]
}
dGraph <- reactive({
f('age')
})
dDataCollege <- reactive({
f('college')
})
La fonction utilisera le nom de la colonne passée dans les appels des lignes 7 et 11 afin d’effectuer ses filtrages et traitements.
Démonstration
Vous pouvez retrouver cette dataviz sur le site de {% link shinyapps https://xincto.shinyapps.io/02-sncf/ %} directement, à noter que si le container doit démarrer les temps de réponse de la première page peuvent être assez longs, j’ai volontairement positionné le timeout à 5 minutes pour limiter la consommation sur leur infrastructure.
Conclusion
Vous avez désormais de quoi vous débrouiller avec ces quelques exemples et fonctionnement de base du moteur shiny. Les prochaines étapes se porteront sur l’hébergement dans un container du produit fini et à l’utilisation de modules graphiques plus aboutis, à suivre donc.